.png)

.jpg)
For multi-table synthetic data generation, one of the most challenging tasks is preserving the relational schema constraints of the original dataset in the synthetic output. This includes maintaining primary key (PK), foreign key (FK), composite key, nullable constraints, and inter-table dependencies.
In this blog, we use a complex football dataset to illustrate the practical challenges of multi-table synthesis and how we address them using Betterdata’s IRG-1 platform.
Data Preprocessing
One issue with the raw football dataset is that it does not fully comply with its declared relational schema. Therefore, a preprocessing step is required to clean and standardize the data before synthesis. Beyond basic cleaning, we apply the following structural adjustments:
- Only 5 leagues are present, so the table is removed, and other tables involving league ID are treated as categorical.
- No textual information would be used in our model, so names, etc., are removed. However, after the removal of these columns, some tables become an ID-only table. To avoid corner case bugs, we insert a placeholder unary value in the tables.
- Some (game + assist provider) in SHOTS are not “appeared” in the same game are transformed into N/A.
- Cyclic dependency between teamstats and games is decomposed into games -> TEAMSTATS -> GAMESTATS.
This transformation ensures a valid directed acyclic graph (DAG) structure for generation.
The full preprocessing script is provided at the end of this blog. The table reference of the processed football dataset is provided at Figure 1, the primary key (PK), foreign key (FK) constraints are explicitly explained at Table 1.
Why This Dataset Is Difficult
To the best of our knowledge, most existing multi-table synthesizers can handle simple PK–FK relationships. However, this football dataset introduces several advanced challenges:
- Composite primary keys (e.g., in APPEARANCES)
- Overlapping composite foreign keys (in GAMES and SHOTS)
- Nullable foreign keys (in SHOTS)
- Non-equality constraints (across GAMES and SHOTS)
- Sequential structure:
- TEAMSTATS sorted by date
- SHOTS sorted by minute
These structural properties significantly increase modeling complexity.
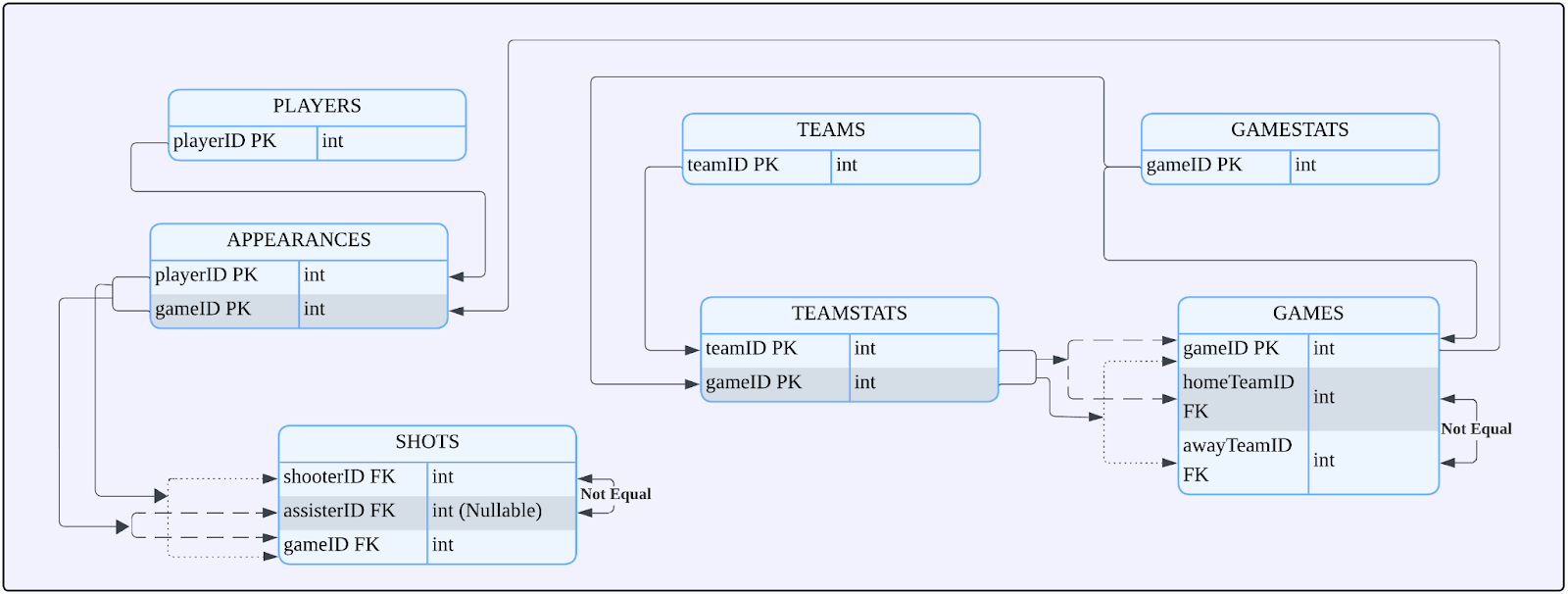
Figure 1. Relational Schema of Football Dataset
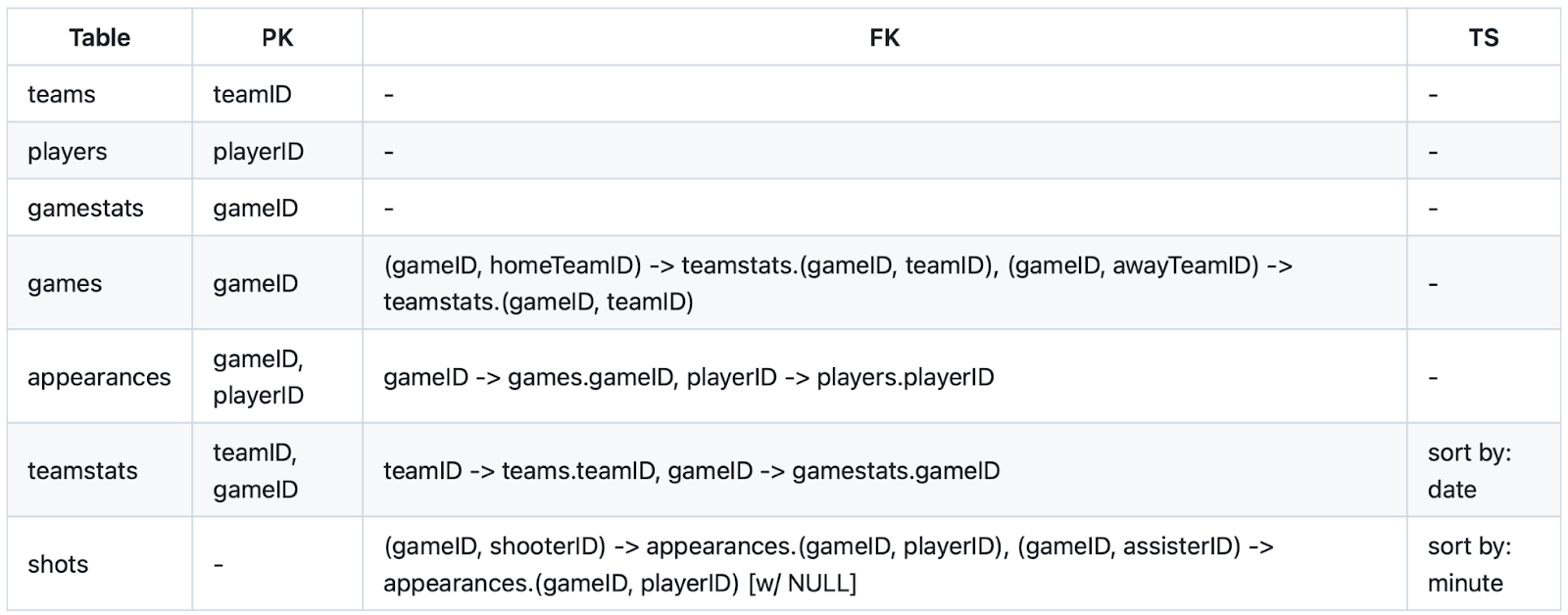
Table 1. Primary Key, Foreign Key Constraints for Football Dataset
IRG-1 Solution
In IRG-1, we systematically address all of the above constraints. Within the IRG-1 platform, users explicitly configure relational constraints before training.
1. Schema Configuration
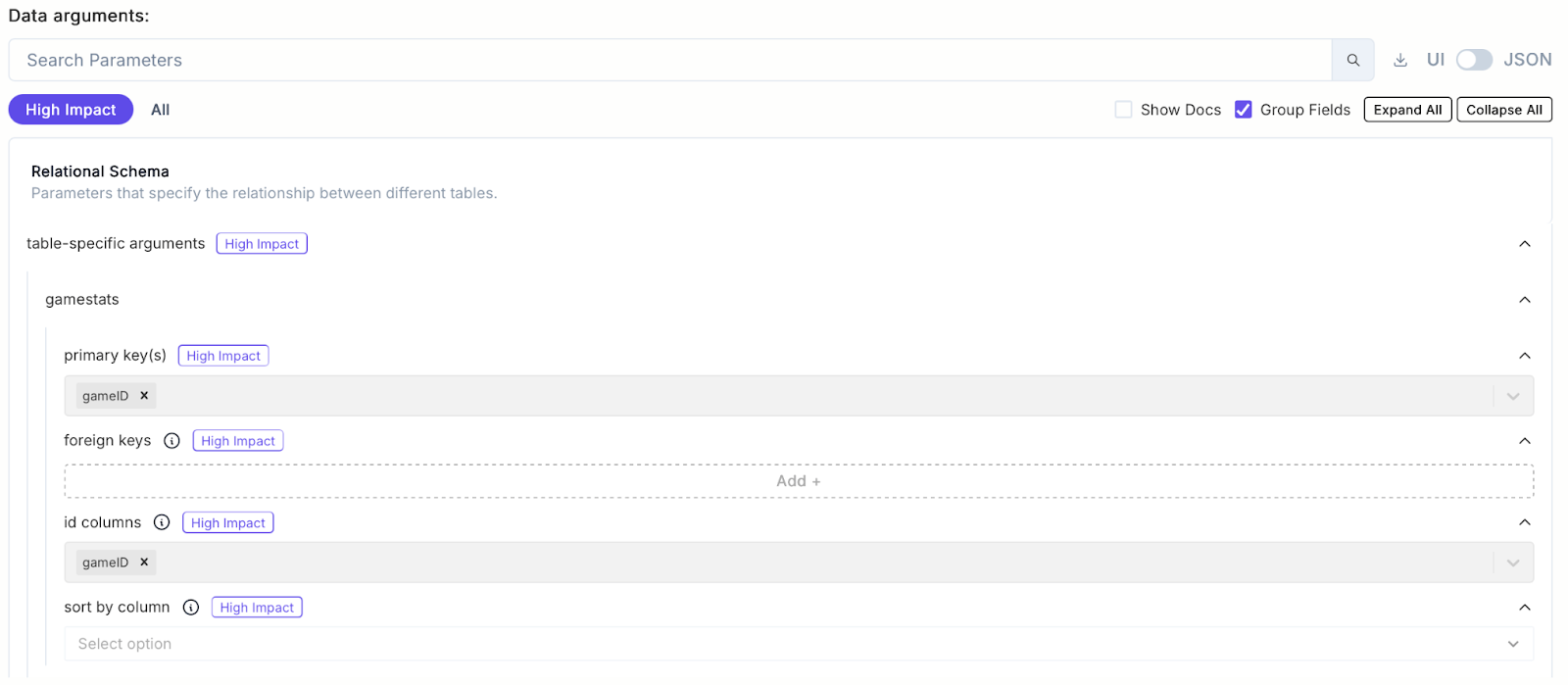
Figure 2. Configuration for Primary Key for GAMESTATS Table in IRG-1
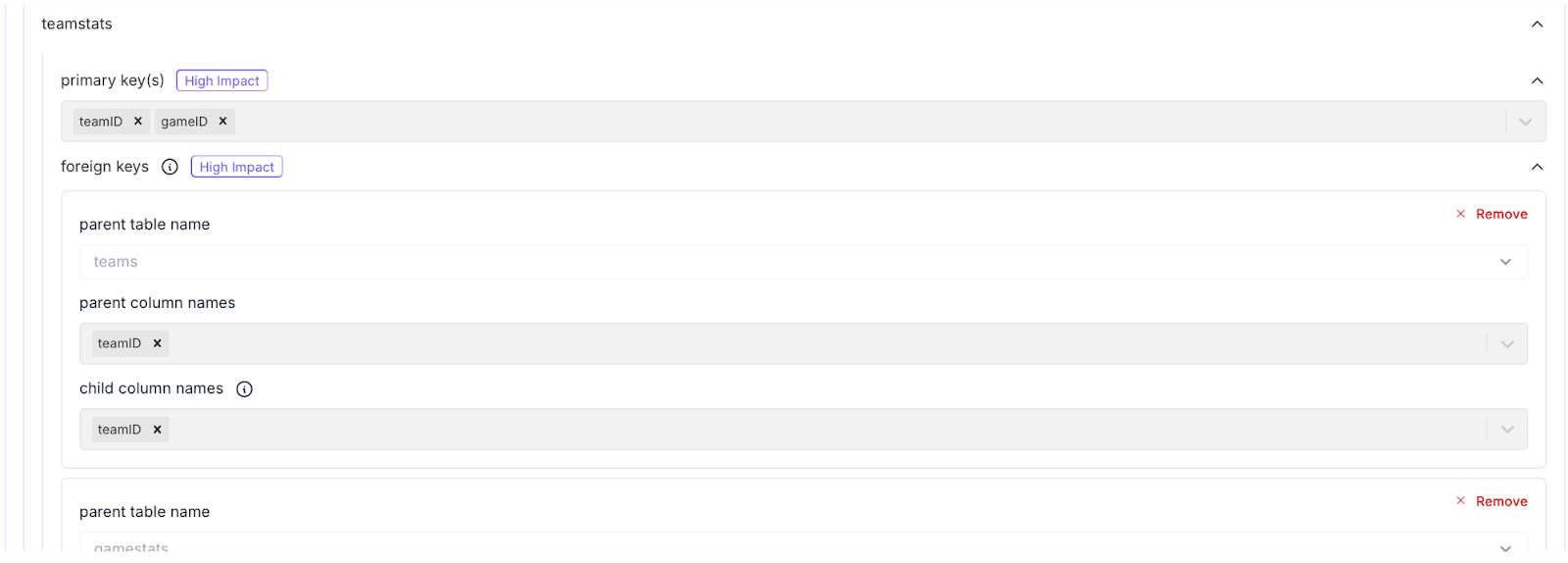
Figure 3. Configuration for Foreign Key for TEAMSTATS Table in IRG-1
2. Topological Generation Order
Beyond schema configuration, IRG-1 requires defining a topological order of tables, which determines the generation sequence. This order must respect inter-table dependencies.
For example:
- APPEARANCES depends on both PLAYERS and GAMES
- Therefore, those parent tables must be generated first
Note that there is not a single valid ordering, but certain precedence rules must always be satisfied.

Figure 4. Topology Order of Football Dataset
3. JSON-Based Configuration
The IRG-1 platform allows toggling between UI mode and JSON mode for schema configuration. This provides flexibility for advanced users and automation pipelines.
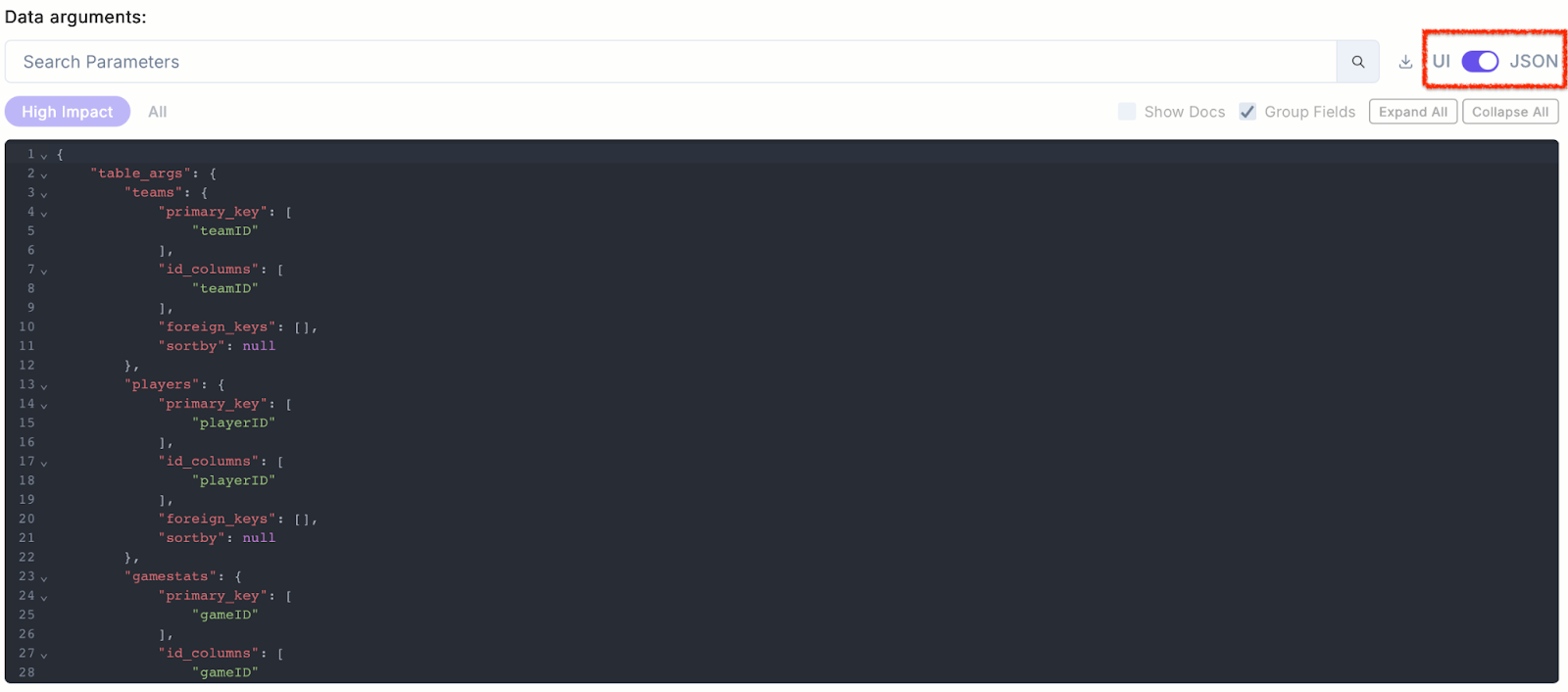
Figure 5. JSON Configuration of Relational Schema for Football Dataset
Result Evaluation
After the model training and data sampling, we will evaluate the synthetic multi-table data quality.
1. Table Shape Consistency
In Figure 6, we can see, our generated data has exactly the same number of columns and rows between real and synthetic data.
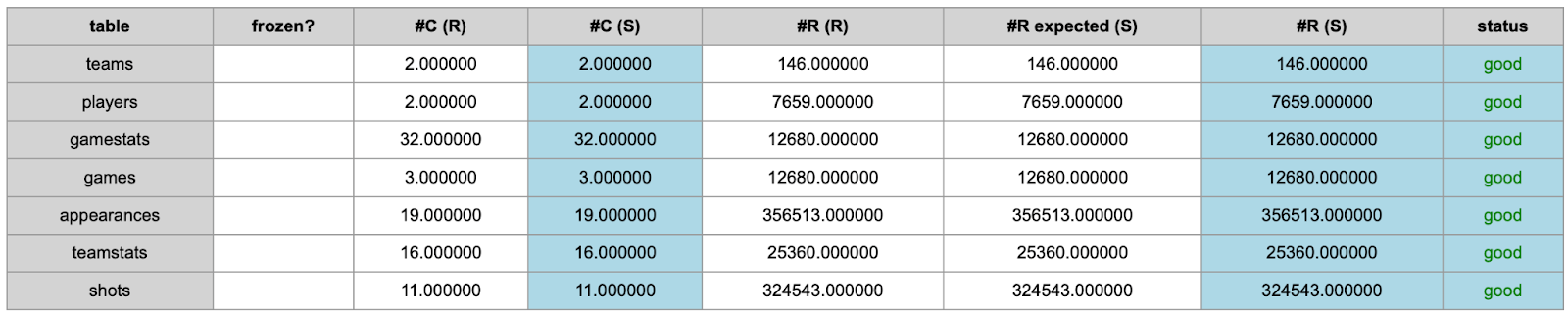
Figure 6. Table shapes of real and synthetic data. #C is the number of columns, and #R is the number of rows.
2. Primary Key Uniqueness
Figure 7 shows that PKs remain unique across all real and synthetic tables.
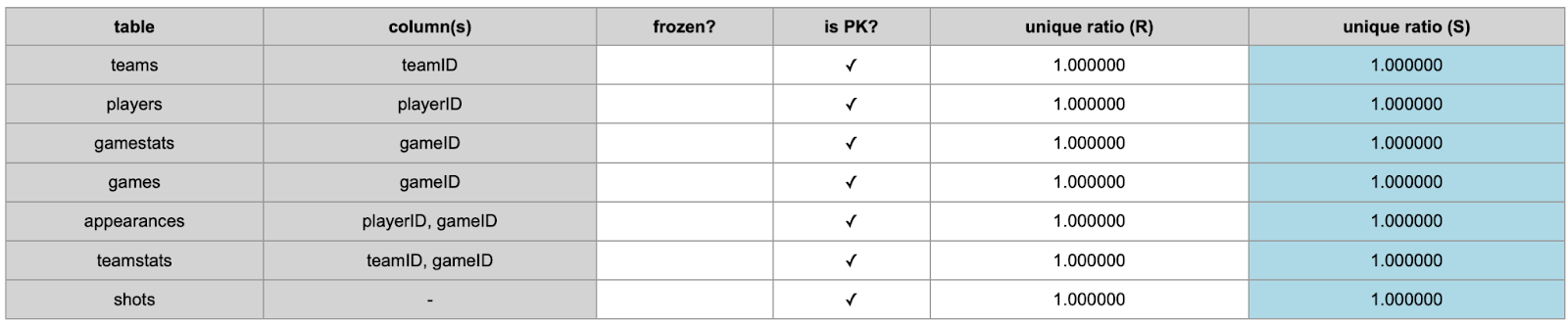
Figure 7. Uniqueness of Primary Key
3. Foreign Key Satisfaction
In Figure 8, we introduce a concept “Degree”: number of child rows corresponding to the same parent row. For example for a player (PLAYERS, i.e., parent table), it can appear (APPEARANCES, i.e., child table) in many games. In our report, we evaluate the degree distribution between real and synthetic data.

Figure 8. Degree Distribution for Three FKs
The relations between different tables in a multi-table dataset are essentially defined by FK constraints. A multi-table dataset is considered valid only if all FK constraints are satisfied. An FK constraint is considered satisfied in the absence of "orphans", i.e., values in the child table that are not found in the parent. Orphans are strictly not allowed for FK constraints satisfaction.
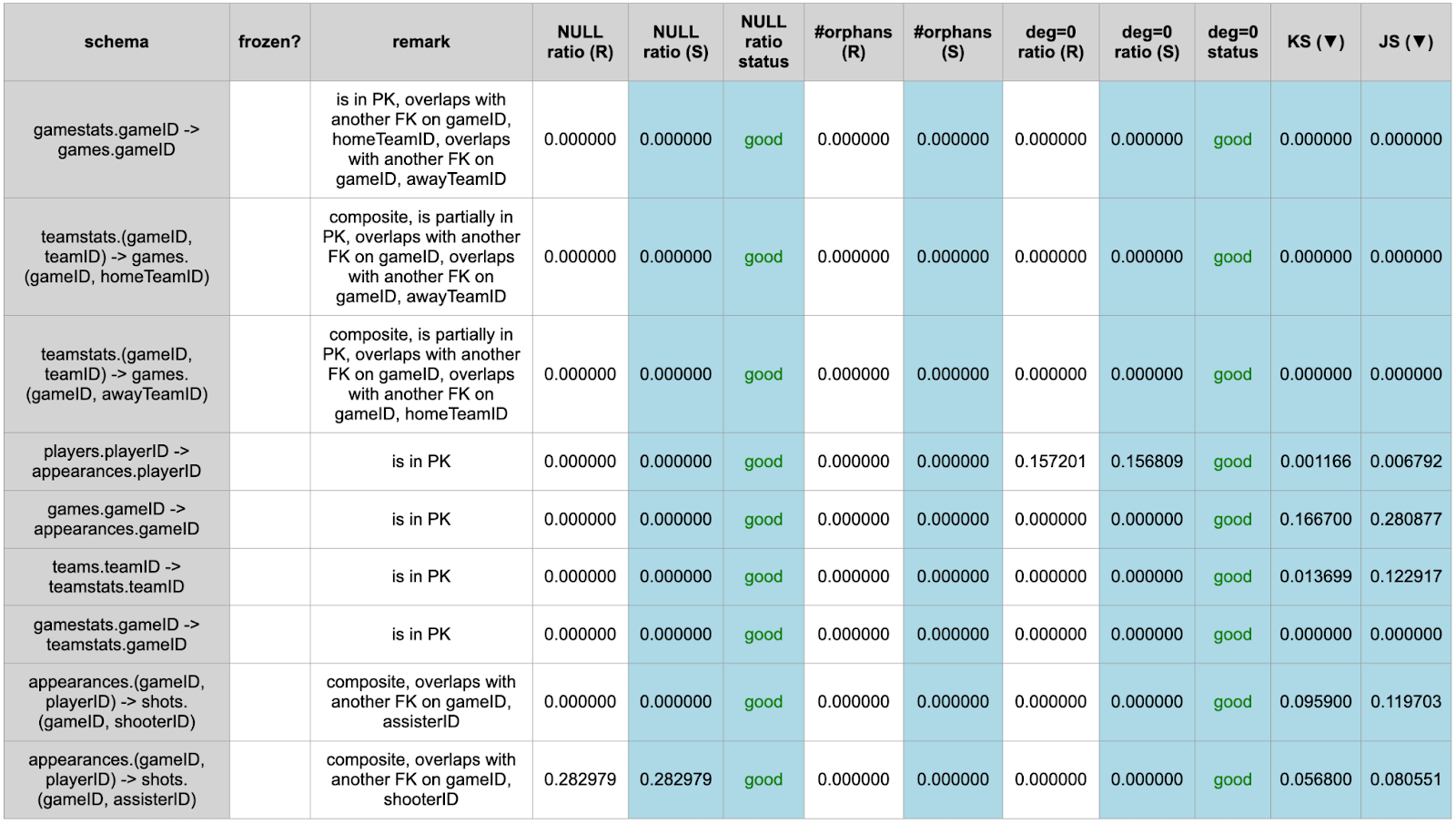
Figure 9. Foreign Key Satisfaction and Statistics of Real and Synthetic Data.
4. Single-Table Statistical Evaluation
We also have more detailed single table evaluation, which include: (1) marginal distribution (2) pair-wise correlation and (3) privacy evaluation. Due to page limits, we will not show all the figures in this blog.
The IRG-1 codebase is publicly available at:
👉 https://github.com/li-jiayu-ljy/irg
If you would like to explore multi-table synthesis for your own structured datasets, feel free to reach out — we would be happy to discuss further.
👉 zilong@betterdata.ai
.jpeg)
