
.jpg)
1. Definition of Synthetic Data:
Synthetic data is a lifelike replica of real data created through Generative Artificial Intelligence (AI). The models that generate synthetic datasets are trained on real data, ensuring that synthetic data mirrors the statistical properties and structure of the real data.

2. Synthetic Data for Data Privacy:
a. Enhanced Privacy:
Since synthetic data does not contain any real data points, it eliminates the risk of exposing sensitive information. This makes it ideal for applications where data privacy is a concern, such as healthcare, finance, and personal data protection.
b. Compliance with Regulations:
Using synthetic data helps organizations comply with stringent data privacy regulations like GDPR and HIPAA, as it removes the need to handle and process real personal data.
c. Safe Data Sharing:
Organizations can share synthetic datasets with partners, researchers, and third-party developers without risking the exposure of sensitive information, facilitating collaboration while maintaining data confidentiality.
3. Synthetic Data for Machine Learning:
a. Abundance of Data:
Synthetic data can be generated in large quantities, providing ample training data for machine learning models. This is particularly beneficial in scenarios where collecting real data is challenging or expensive.
b. Balanced Datasets:
Synthetic data can be used to augment real datasets, address class imbalances, and improve machine learning models' performance. For example, it can generate more examples of rare classes in classification tasks.
c. Scenario Testing:
Machine learning models can be trained and tested on a variety of synthetic scenarios that might not be present in real data, enhancing their robustness and ability to handle edge cases.
d. Innovation and Experimentation:
Synthetic data allows researchers and developers to experiment with new algorithms and techniques without the constraints imposed by real data availability and privacy concerns.
Read more on improving machine learning models with synthetic data here.
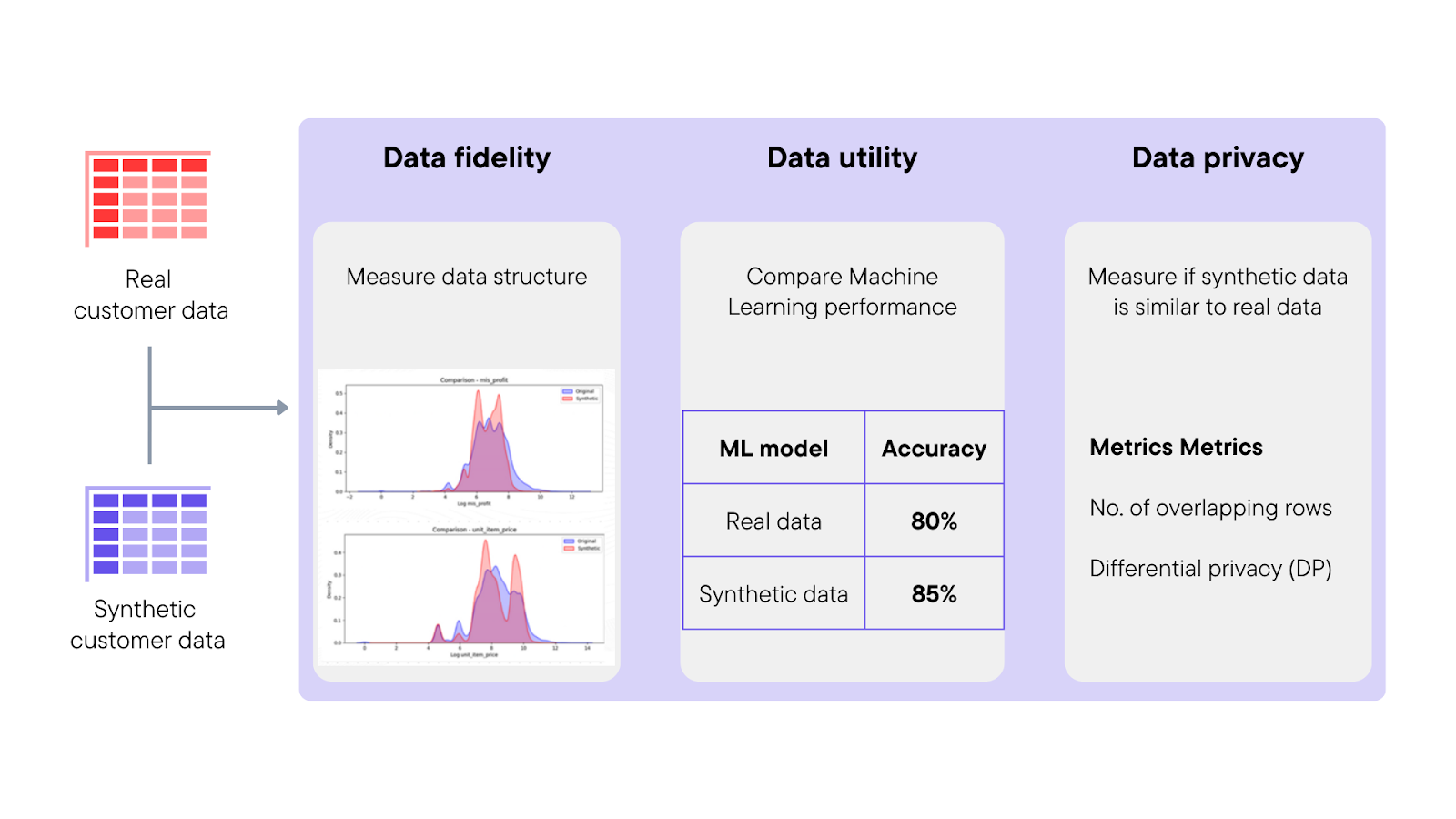
3. Types of Synthetic Data:
a. Fully Synthetic Data
Fully synthetic data is entirely generated by algorithms without direct reliance on real-world data. This type of data is created from models trained on real data but does not include any real data points.
Key Characteristics:
- Privacy: No direct link to real-world individuals, ensuring privacy.
- Versatility: Can be generated in large quantities to meet specific requirements.
- Quality Control: The quality of fully synthetic data depends heavily on the underlying model's accuracy and robustness.
Use Cases:
- Training machine learning models when real data is sensitive or limited.
- Testing software systems under various scenarios that might not be covered by real data.
- Creating datasets for benchmarking algorithms.
b. Partially Synthetic Data
Partially synthetic data, also known as hybrid synthetic data, combines real data with synthetic elements. This approach generates synthetic values for some parts of the dataset while retaining actual data points for other parts, maintaining a balance between data utility and privacy.
Key Characteristics:
- Combination of Real and Synthetic: Contains both real and synthetic elements.
- Enhanced Privacy: Reduces the risk of re-identification by altering sensitive parts of the data.
- Utility Retention: Maintains the utility of the original dataset by preserving key patterns and correlations.
Use Cases:
- Replacing sensitive attributes in a dataset to protect privacy while keeping non-sensitive data intact.
- Augmenting real datasets with synthetic data to address class imbalances or to test specific conditions.
- Sharing datasets for research or collaboration without exposing sensitive information.

4. Classes of Synthetic Data
a. Synthetic Text Data
Synthetic text data involves generating artificial textual content using natural language processing (NLP) techniques. This can include sentences, paragraphs, documents, or any other form of written text. The generation of synthetic text can serve various purposes, from training conversational agents to creating large datasets for linguistic research.
Key Characteristics:
- Language Models: Generated using advanced models such as GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), or other NLP frameworks. These models can produce coherent and contextually relevant text.
- Contextual Coherence: The generated text must maintain grammatical correctness and contextual relevance, ensuring it makes sense within the intended application.
- Application Specificity: Synthetic text can be tailored for specific domains, such as legal, medical, or technical texts, making it suitable for domain-specific applications.
Use Cases:
- Training Chatbots and Virtual Assistants: Synthetic text data can be used to train chatbots and virtual assistants, enabling them to understand and respond to a wide range of user queries.
- Creating Large Corpora for Text Analytics and NLP Research: Researchers can generate vast amounts of text data to train and test NLP models, aiding in advancements in the field.
- Testing and Validating Text-Based Software Systems: Synthetic text can be used to test the functionality and performance of text-processing software systems, ensuring they can handle diverse linguistic inputs.
b. Synthetic Tabular Data
Synthetic tabular data involves generating datasets structured in rows and columns, similar to spreadsheets or database tables. Each column represents a variable, and each row represents a data point. This type of synthetic data is crucial for various analytical and machine learning tasks.
Key Characteristics:
- Structured Format: Synthetic tabular data consists of numerical, categorical, or mixed-type columns, mimicking the structure of real datasets.
- Statistical Properties: It preserves the statistical properties and correlations of the original data, ensuring the synthetic data is a reliable representation.
- Data Augmentation: Synthetic tabular data can augment real datasets by providing additional synthetic data points, improving the robustness of machine learning models.
Use Cases:
- Building and Testing Machine Learning Models: Synthetic tabular data is used for training models in tasks such as classification, regression, and clustering, ensuring the models perform well on varied data.
- Conducting Data Analysis and Statistical Testing: Analysts can use synthetic data to explore patterns, test hypotheses, and validate analytical models without compromising real data privacy.
- Simulating Business Scenarios and Performing What-If Analyses: Businesses can create synthetic datasets to simulate various scenarios and perform what-if analyses, aiding in strategic decision-making.
c. Synthetic Media Data
Synthetic media data encompasses artificially generated images, videos, sounds, or any other multimedia content. This type of data is created using advanced techniques, including generative adversarial networks (GANs) and other deep learning models, to produce high-quality, realistic media.
Key Characteristics:
- Realism: High-quality synthetic media closely resembles real-world media, making it suitable for realistic simulations and training data.
- Versatility: Synthetic media is applicable to a wide range of media types, including images, videos, and audio, offering broad utility across different domains.
- Complexity: Generating convincing synthetic media requires sophisticated models that can accurately replicate the intricacies of real media.
Use Cases:
- Creating Training Data for Computer Vision and Audio Recognition Systems: Synthetic media provides ample data for training models in computer vision and audio recognition, enhancing their performance.
- Generating Content for Virtual Reality (VR) and Augmented Reality (AR) Applications: Synthetic media can be used to create immersive and interactive content for VR and AR applications, enriching user experiences.
- Developing and Testing Media Processing Algorithms: Researchers and developers can use synthetic media to develop and test new algorithms for media processing, ensuring they work effectively across different types of media.
5. Conclusion
Understanding the types and Classes of synthetic data is crucial for data scientists and researchers. Fully synthetic and partially synthetic data offer different levels of privacy and utility, catering to various needs. The variety in synthetic data—from text and tabular to media—opens numerous possibilities for applications in machine learning, software testing, data analysis, and beyond. By leveraging synthetic data, organizations can innovate and explore new frontiers while maintaining ethical standards and privacy considerations.
