
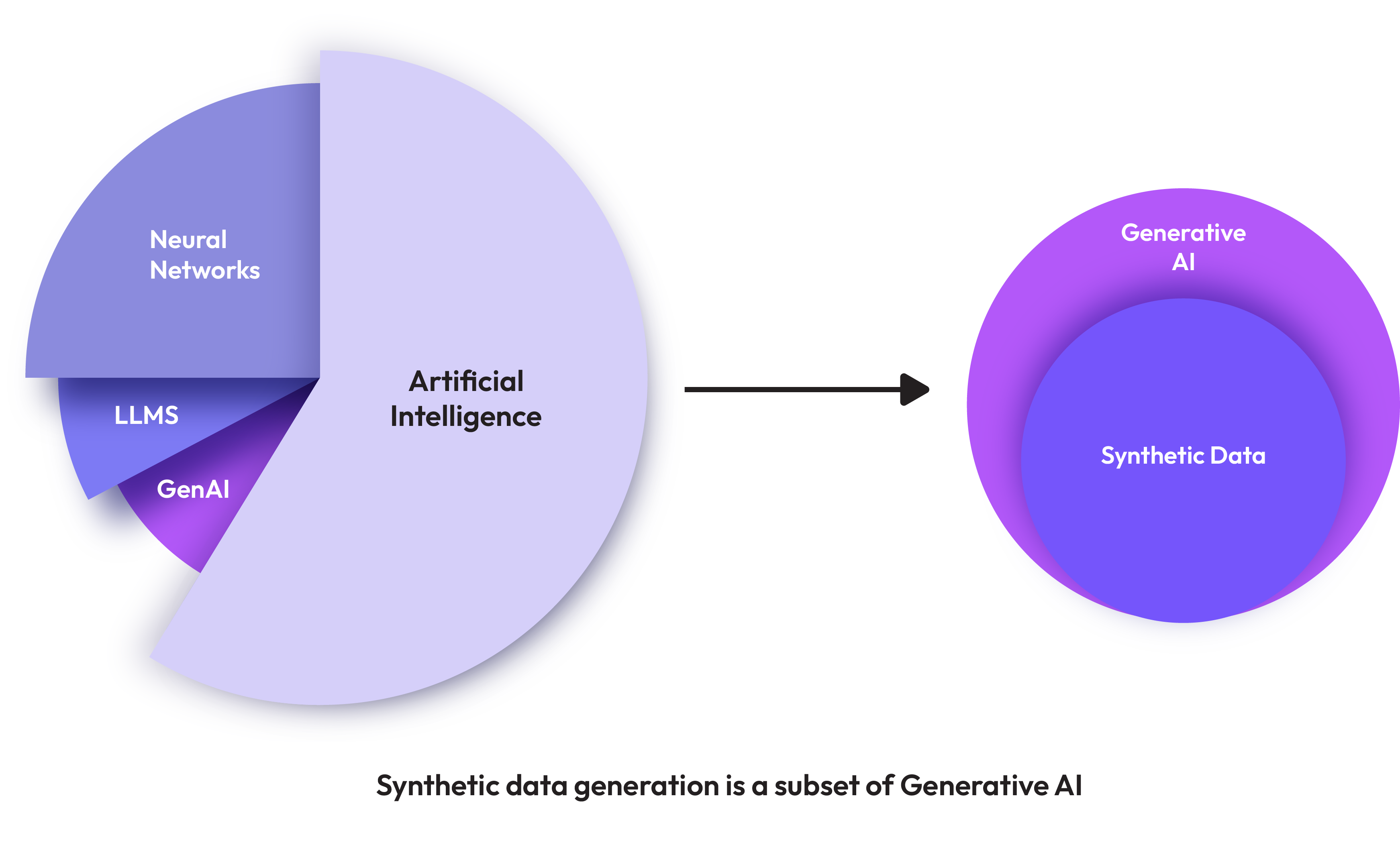
Synthetic data is created through Generative Artificial Intelligence (AI) that is trained on real data first, and after training, untraceable datasets can be generated that have nearly identical statistical properties and structure as of the real data. Secondly, generative AI models are trained to mimic prominent statistical patterns in the data without memorizing any individual-specific details. As such, they can create artificial data that seems real, with random unique features, yet it's impossible to trace back to any actual individual. Therefore, it is not subject to any data privacy and protection laws globally. This is why synthetic data can be used much more easily by companies as compared to using real data.
Table of Contents:
In this world, a business is either data-driven or likely to fail. This is especially true for companies and tech startups that rely on Artificial Intelligence (AI) and Machine Learning (ML) for their product development and growth. As the world looks towards automation, especially in consumer markets, data becomes the single most important factor determining how successful a company will be today and in the future.
However, using real data is a growing liability because of increasing data protection regulations globally. There are more than 130 countries enforcing data privacy laws in the world right now that restrict access, use, and transfer of real data. And the consequences of non-compliance and breaking these laws are severe. Even if you are not breaking any laws, there is always the possibility of a hack or a data leak that can destroy a company’s reputation instantly. According to IBM USD 4.45 million was the global average cost of data breaches in 2023. These risks are not a matter of if but when. So, instead of being reactive, how can companies be proactive about compliance and future-proof their businesses?
This is where Synthetic Data plays a critical role and is increasingly becoming so important to businesses around the world. It is artificially generated information that mirrors the characteristics of real data without containing any personally identifiable information (PII) and eliminates any risk of exposing real or sensitive user information. This means as a Chief Technology Officer (CTO) or a Product Leader, you can now confidently develop, test, and optimize your algorithms and products while ensuring privacy compliance. For organizations operating in the finance, healthcare, and government domains that are governed by the most stringent data regulations out there, synthetic data enables quick access and easy flow of data while supporting comprehensive testing and validation of systems and training robust AI/ML models without worrying about leaking or handling sensitive information.

With increasing concerns over data breaches and stringent data privacy regulations, synthetic data allows businesses to easily access and share data without compromising the confidentiality of business-sensitive information or the privacy of sensitive real user information. This not only ensures compliance with privacy laws, but also builds trust among users by reducing the risks associated with data breaches, data leaks, and ransomware attacks. As synthetic data cannot be used to infer about any real individual, businesses can use it as a substitute for real data and no longer worry about paying fines for non-compliance with privacy laws globally.
Think of a chatbot that isn’t just a chatbot but an AI-enabled assistant that helps consumers pick which color would look better on them. Now think of the amount of data required and the cost to acquire that data. Synthetic data eliminates the need for exhaustive and potentially expensive real data acquisition. Instead, companies can generate diverse datasets through GenAI by utilizing public and private data to generate privacy-preserving synthetic data, or limited datasets to augment data and fulfill different ML performance needs on demand, facilitating cost-effective innovation. This opens up major avenues for startup growth and smaller enterprises looking to compete on a data-driven playing field without the financial burden of large-scale data collection.
Unlike real data, synthetic datasets can be easily scaled to meet the demands of various testing scenarios and to interpolate the available real data. Whether simulating user behavior, market trends, or anomalies, synthetic data allows businesses to flexibly adapt to evolving needs without the constraints of limited, pre-existing datasets. This allows organizations to have quick access to reliable datasets that can be used to train AI/ML models in different scenarios as well as build other data-driven solutions.
However, it is worth noting that the random features introduced by GenAI to make synthetic data non-identifiable also shift the distribution away from that of the real data. This means the 'new trends' that your synthetic data might have are not real trends but simulated ones. In short, you cannot create new information from old information. GenAI only solves the operational limitations of less data, not the information-theoretic ones.
Synthetic data provides a controlled environment for testing and AI/ML training, enabling companies to mitigate biases that may exist in real data. Such as a larger percentage of a specific gender or ethnicity. This is particularly crucial for industries like finance and healthcare, where fair and unbiased algorithms play an important role in policy development, product innovation, and distribution of funds.
Synthetic data facilitates seamless collaboration among teams by providing a privacy-safe alternative for sharing datasets. This accelerates the pace of innovation as data scientists, analysts, and developers can collaborate without the barriers imposed by data privacy concerns. Synthetic data decreases the time to share data from months to days enabling faster growth at scale.
Read more about advantages of using synthetic data here.
In the finance industry, where precision and data privacy are paramount, synthetic data becomes a game-changer. It facilitates rigorous testing of algorithms for risk assessment, fraud detection, and customer profiling without compromising sensitive financial information. Financial institutions can optimize AI/ML models and strategies while adhering to stringent privacy regulations, ensuring the security and confidentiality of user data.
Healthcare, characterized by small datasets and privacy concerns, benefits significantly from synthetic data. It accelerates medical research by enabling the development and testing of algorithms without exposing real patient data as well as increasing the quantity of the real patient data by 10-20 times. This opens avenues for breakthroughs in diagnostics, treatment personalization, and drug discovery while maintaining the highest standards of patient privacy and compliance with healthcare regulations.
In the retail sector, where customer insights are key, synthetic data facilitates innovation in product development, pricing strategies, and personalized marketing. Retailers can create simulated customer profiles to test the effectiveness of marketing campaigns, optimize inventory management, and enhance the overall customer experience. This data-driven approach ensures that retail strategies are finely tuned to meet the evolving demands of the market.
For the telecommunications industry grappling with the challenges of network optimization and Quality-of-Service (QoS), synthetic data allows for realistic simulation of network conditions, enabling rigorous testing of new technologies, predictive maintenance, and optimization of network infrastructure. This ensures that telecom companies can deliver seamless connectivity and improve the overall performance of their networks without the need to expose real user data.
Learn more about industry specific uses cases of synthetic data here.
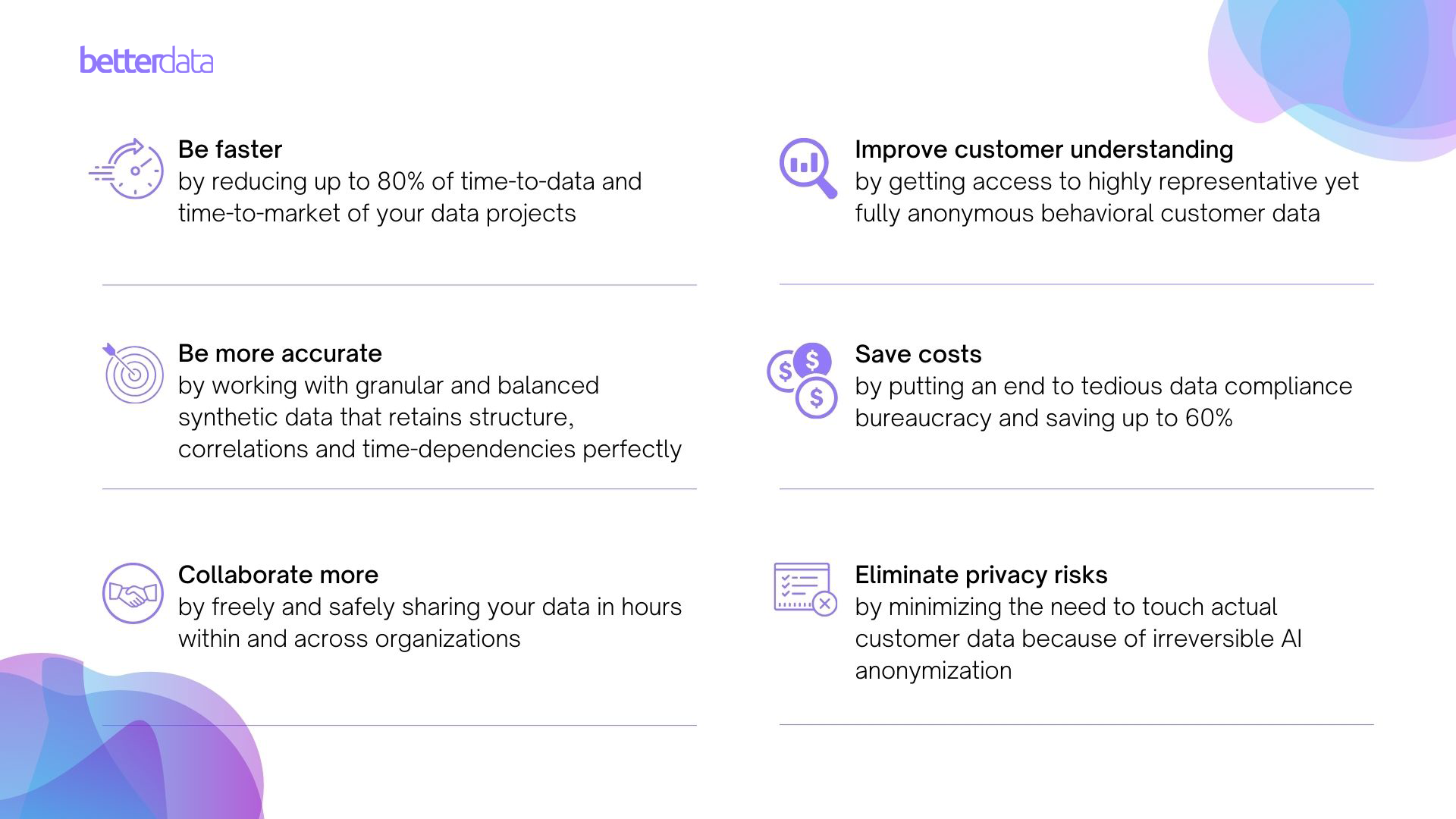
Data Scientists can use synthetic data to create effective and efficient data patterns and more accurate AI/ML models. Synthetic data allows them to create diverse and scalable datasets for testing and training algorithms. By providing a controlled environment that mimics real-world scenarios, data scientists can fine-tune models without compromising sensitive information. This not only streamlines the development process but also enhances the accuracy and robustness of predictive models, ultimately contributing to more informed decision-making. Synthetic data is especially the best choice for data scientists if they are working on AI/ML use cases that require real user data.
Data Protection Teams operate on the front lines of safeguarding user privacy and ensuring compliance with the ever-increasing data protection regulatory landscape. Synthetic data is a strategic asset for them. It allows these teams to worry less about what the privacy laws dictate and find ways to meet compliance requirements faster. For example, a use case built with real data needs explicit user consent. With synthetic data, user consent is not needed and therefore, it saves these teams months’ worth of time. By creating artificial datasets that retain the statistical characteristics of real data, data protection teams can ensure that their legal measures are effective, compliant, and adaptable to evolving regulatory landscapes, enabling them to improve their defenses against potential breaches and privacy concerns as well as making their lives so much easier.
For Product Developers engaged in the creation and optimization of innovative solutions, synthetic data opens various possibilities. Whether developing software, applications, or advanced technologies, product developers benefit from the flexibility and scalability that synthetic data offers. It accelerates the testing and refinement phases, allowing developers to iterate quickly and efficiently as all team members can work on the same datasets without worrying about the long approvals required for sharing and accessing data. Synthetic data ensures that products are rigorously tested in diverse scenarios without exposing them to the challenges associated with handling real-world sensitive data. This not only expedites the development lifecycle but also mitigates risks and enhances the overall quality of the end product. With synthetic data, product developers can accelerate their time-to-market from months down to days.
Data Engineers, responsible for the architecture and maintenance of data infrastructure, find synthetic data invaluable in optimizing their workflows. Synthetic data can help in the development and testing of data pipelines, allowing engineers to identify and address potential bottlenecks or vulnerabilities. It provides a controlled environment for troubleshooting and enhancing the efficiency of data processing systems, contributing to the overall robustness of their data infrastructure.
Lean more about the importance of synthetic data for data scientists and privacy teams here.
By leveraging advanced algorithms and modeling techniques, organizations can generate artificial datasets mirroring real-world scenarios. This process not only ensures privacy compliance but also provides a better alternative to real data. For example, Betterdata has trained algorithms by using state-of-the-art models such as Generative Adversarial Networks (GANs), Diffusion models, Transformers, and Large-Language Models (LLMs) with cutting-edge privacy engineering techniques to generate highly realistic and privacy-preserving synthetic data.
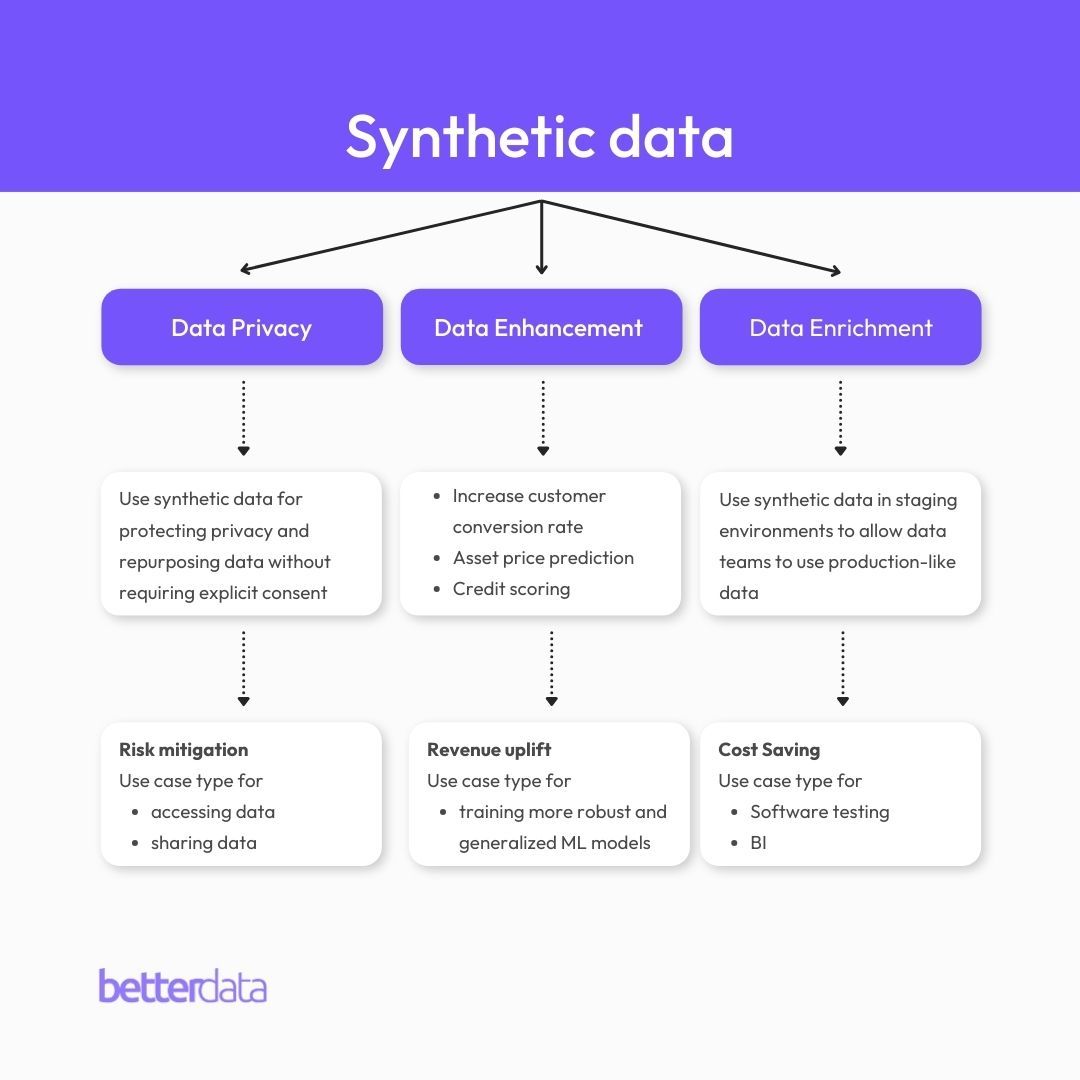
Synthetic data is all about generating artificial datasets that look and function like real-world data without containing real user or business-sensitive information. It offers good guarantees for data privacy, data security, data quality, data quantity, and data coverage, making it a very powerful tool for industries working with data.
On the other hand, data anonymization focuses on destroying, masking, or redacting PII data and suppressing non-PII information within a dataset. This method is non-AI based and involves techniques such as pseudonymization, data masking, generalization, data swapping, data perturbation, encryption, tokenization, and generalization to protect individual identities as well as their behavioral attributes.
In summary, anonymization techniques operate on this fundamental principle: destroy information to protect privacy and vice versa. Secondly, anonymization is a non-AI-based method, which is why it is not scalable as different techniques need to be applied to different data types, has high privacy risks, is vulnerable to user re-identification risks, and cannot be used to train ML models. Anonymization also cannot be used to generate more data from limited data.
Synthetic data, on the other hand, is an AI method that is scalable as the AI models can automatically understand different data types in a supervised or unsupervised manner. Since synthetic data is artificially generated, it does not belong to real users anymore and therefore, it has low privacy and user re-identification risks. Finally, synthetic data can be used to train ML models resulting in more robust and generalized algorithms. One of the main differentiating factors for synthetic data is the ability to generate more data from limited data. All these properties position synthetic data as a key technology and the only viable solution to not only address data privacy but also data enhancement and data enrichment challenges faced by data teams and professionals.
Lean more about the difference between synthetic data and data anonymization here.
Although synthetic data is poised to solve data privacy and data quality challenges, it comes with its own set of limitations. The key challenges in synthetic data can be divided into four categories explained below:
This process essentially deals with whether a user can take real data and pre-process it in a way that is fit for input to a synthetic data generation algorithm. This can include steps like automatic detection of data types in a column (Categorical, Numerical, Date, Time, etc.), checking for missing values, inaccuracies, duplicates, and skewness in a dataset, dealing with categorical values, etc. Generally, this process can include the following types of analysis:
A key challenge here is how to deal with outliers such that when you have a dataset with a few samples about a certain population, what can be done to avoid the synthetic data generation model from overfitting? The risk here is if a model overfits, it can memorize data instead of learning it and that leads to privacy leakage. Another challenge is how to handle data at scale: how to process a dataset in a distributed way, whether to use binary formats (Parquet, HDF5) or non-binary formats (CSV, Excel), should the entire dataset be loaded into memory first or can it be processed as it is read in a streaming fashion. The risk here is subject to business requirements as it may be difficult to generate synthetic data at scale if data cannot be prepared for the synthetic data generation algorithm.
This process deals with the generation of synthetic data. For this process, an AI algorithm is required based on your metadata. Next, using real data, the model is trained which can take a few minutes to a few hours to a few days, subject to compute resources a user has. In the training phase, the model will learn patterns from the real data and once training is finished, the model can be used to generate synthetic data artificially from scratch. A key challenge here is how to avoid the model from overfitting and the associated risk is that if the model overfits, it can generate real data samples as synthetic output.
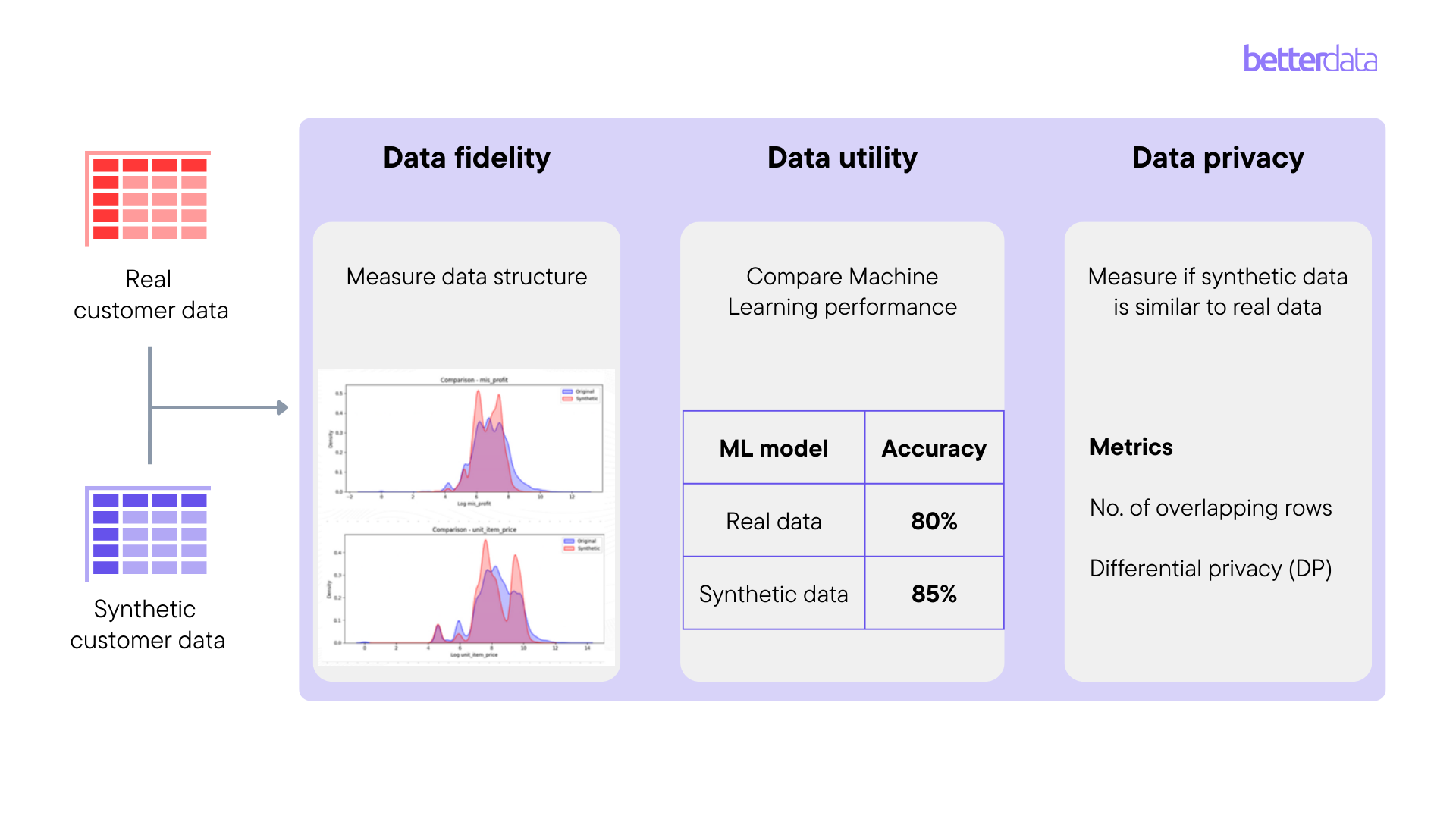
After synthetic data is generated, it can be compared with real data on three bases:
A key challenge here is there is no unified evaluation framework for synthetic data and as such, it is difficult to quantify data privacy and data quality guarantees. The risk associated with it is that without effectively proving how good synthetic data is, its adoption can be limited.
Data teams typically work hand in hand with business units and legal teams. The challenge here is natural: data teams are technical and demand high data quality guarantees from synthetic data, whereas legal teams are non-technical in nature and demand high privacy guarantees from synthetic data. This creates a dilemma on whether to optimize synthetic data for quality or privacy, as doing so for both is just simply not possible. The associated risk here is since there are no concrete guidelines on using synthetic data for different applications, business owners are skeptical of it and resist its value propositions.
As the world moves towards digitization, automation, AI, and augmented reality, synthetic data presents itself as an enabler; creating and supporting the free flow of high-quality data among organizations to be used for AI/ML, Business Intelligence (BI), data licensing, product testing and development, policy development and so much more without having to worry about non-compliance with data protection regulations. With synthetic data, businesses can minimize the potential risks of lawsuits and brand reputation. It opens up new avenues for innovation and collaboration among data professionals, teams, and organizations alike, fostering huge growth potentials and use cases that were just not possible before.
