.png)

.jpg)
Enterprise AI development is constrained by data access, privacy risk, and operational governance. Financial institutions and regulated enterprises must balance two conflicting requirements: enabling large-scale data usage for AI while preventing exposure of sensitive customer information.
Synthetic data solves this by enabling organizations to develop, test, and train machine learning models without exposing real customer data.
In this blog, we examine the architecture, scaling model, and operational framework for deploying synthetic data in enterprise environments.
1. The Enterprise Data Bottleneck:
Modern organizations generate and store massive volumes of sensitive operational data. However, using this data outside production environments introduces multiple risks:
- Regulatory violations
- Data leakage exposure
- Compliance overhead
- Long approval cycles for data sharing
In many banking environments, data sharing for development or analytics can take months, while operational systems process millions or billions of records daily.
To mitigate this, enterprises increasingly adopt a dual-data architecture:
- Real data remains strictly isolated within production systems.
- Synthetic data is used for development, testing, and AI training.
This approach eliminates the need to replicate sensitive customer datasets across environments.

2. Betterdata Synthetic Data Generation Architecture:
Enterprise synthetic data systems must operate within high-security infrastructure constraints.
The architecture used by Betterdata is designed for on-premise and air-gapped environments, enabling deployment inside banking and government systems without external connectivity.
Key architectural characteristics include:
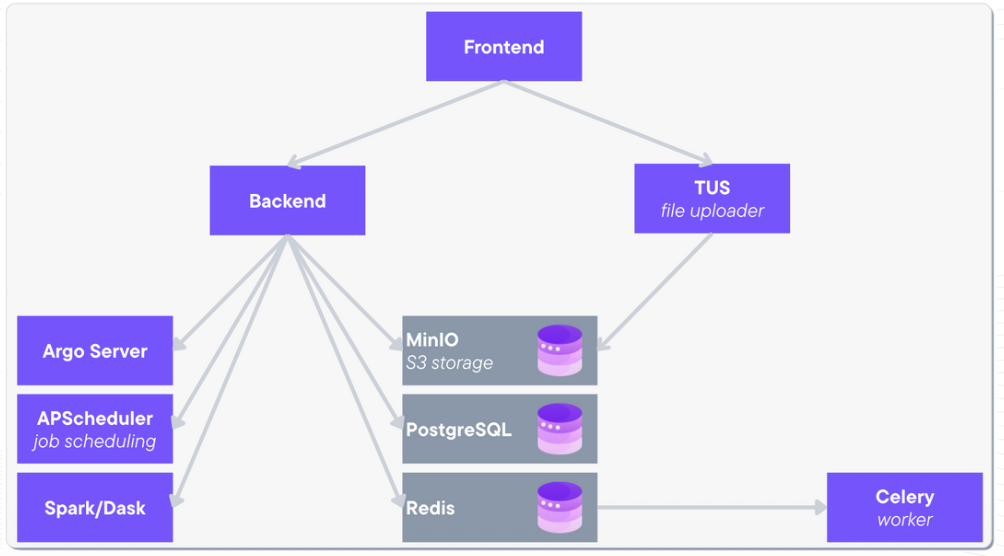
a. Modular Microservices:
The platform is deployed as isolated microservices, improving fault tolerance and enabling horizontal scaling. Each component performs a specific function in the synthetic data pipeline.
b. Core Platform Components:
The architecture includes:
- Frontend UI server – user interface and management
- Backend server – platform logic and orchestration
- TUS server – large dataset ingestion
- Celery workers – asynchronous task processing
- Spark / Dask clusters – distributed data computation
- Argo server – workflow orchestration
- APScheduler – time-based pipeline scheduling
Supporting storage infrastructure includes:
- MinIO – S3-compatible object storage
- PostgreSQL – relational metadata storage
- Redis – high-speed caching layer
All services operate inside private infrastructure environments to ensure data sovereignty and regulatory compliance.
3. Synthetic Data Without Real Data Sharing
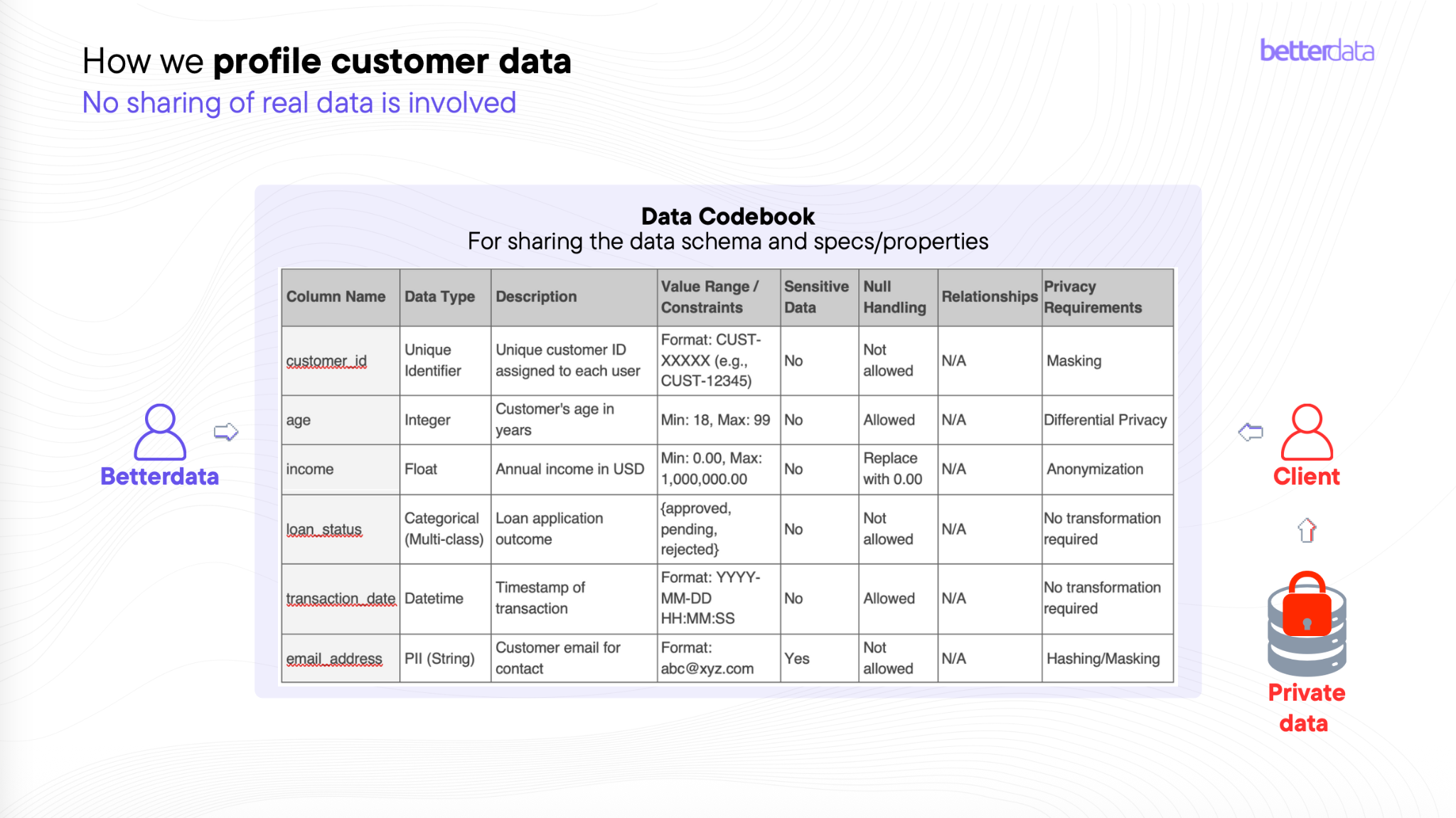
A critical design principle of enterprise synthetic data systems is zero sharing of real data outside secure environments.
Instead of transferring datasets, the platform uses a data codebook that describes the structure and constraints of the original dataset.
The codebook defines:
- column names
- data types
- value ranges
- null handling rules
- relationships between fields
- privacy controls such as masking or hashing
Using these specifications, synthetic data models generate datasets that preserve statistical characteristics without exposing actual records.
4. Synthetic Data Models
Different synthetic data generation models are used depending on dataset characteristics and scale.
Typical approaches include:
a. Tree-Based Models:
High-data environments favor tree-based architectures due to efficiency and scalability.
b. GAN and Deep Learning Models:
Generative adversarial networks are commonly used when datasets contain balanced distributions requiring higher fidelity.
c. LLM-Based Generators:
When data availability is limited, large language models can generate synthetic tabular data using pretrained knowledge.
The platform evaluates synthetic data quality using multiple criteria:
- statistical similarity
- correlation preservation
- privacy leakage risk
- ML model performance on synthetic datasets
This ensures synthetic data retains utility for machine learning while maintaining privacy guarantees.
5. Scaling Synthetic Data Projects:
Synthetic data adoption follows a structured scaling process from experimentation to enterprise production.
a. Phase 1: Proof of Concept
Typical scale:
- 10 million rows
- 50 features
- ~5 relational tables
Infrastructure is minimal because compute workloads are handled by the platform.
b. Phase 2: Pilot Deployment
Typical scale:
- 100 million rows
- 500 features
- ~10 relational tables
Infrastructure requirements include:
- 16 CPU cores
- 64 GB RAM
- GPU acceleration (A100 / H100)
c. Phase 3: Production
Enterprise production environments can reach:
- 1+ billion rows
- 1000+ features
- 100+ tables
Production deployments require multi-GPU compute clusters to support large-scale synthetic data generation.
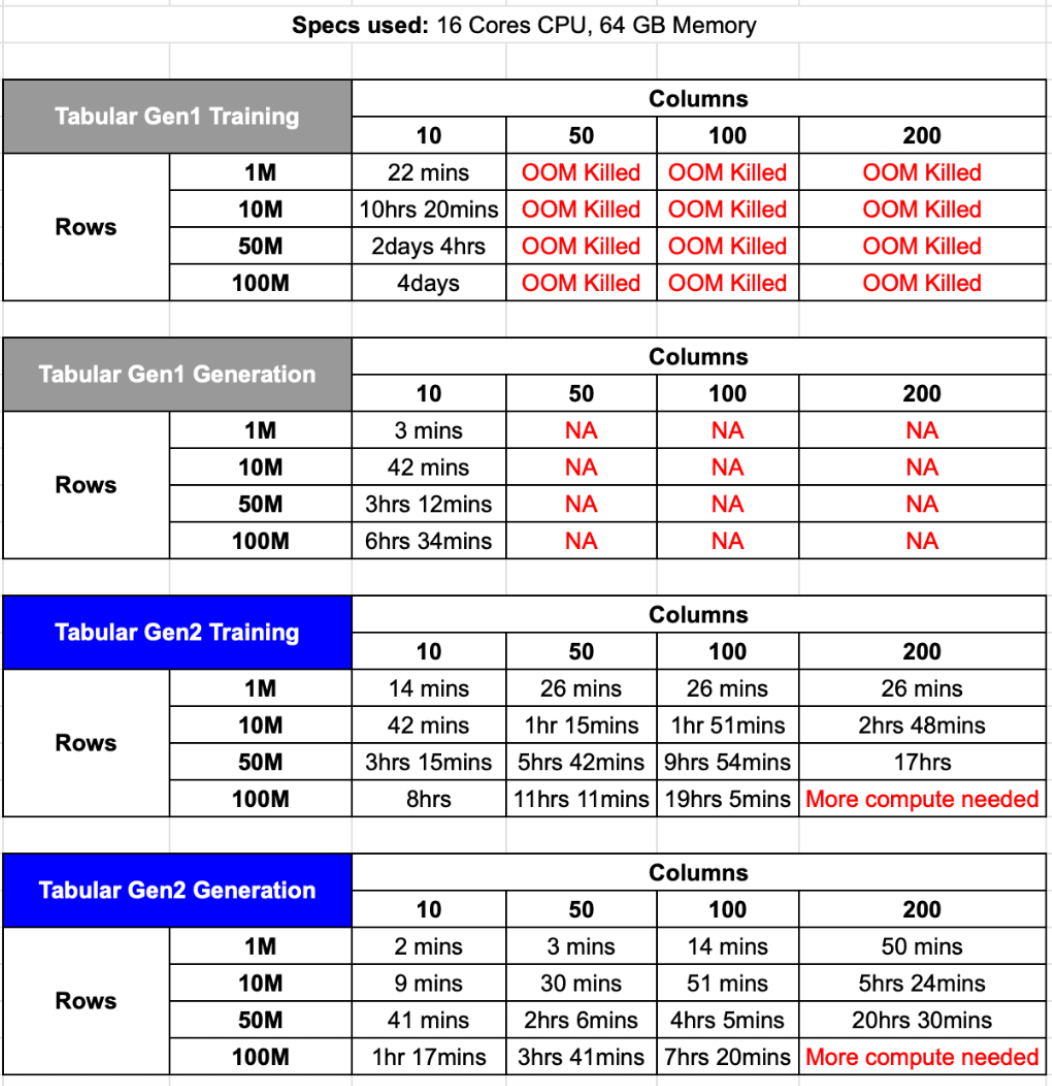
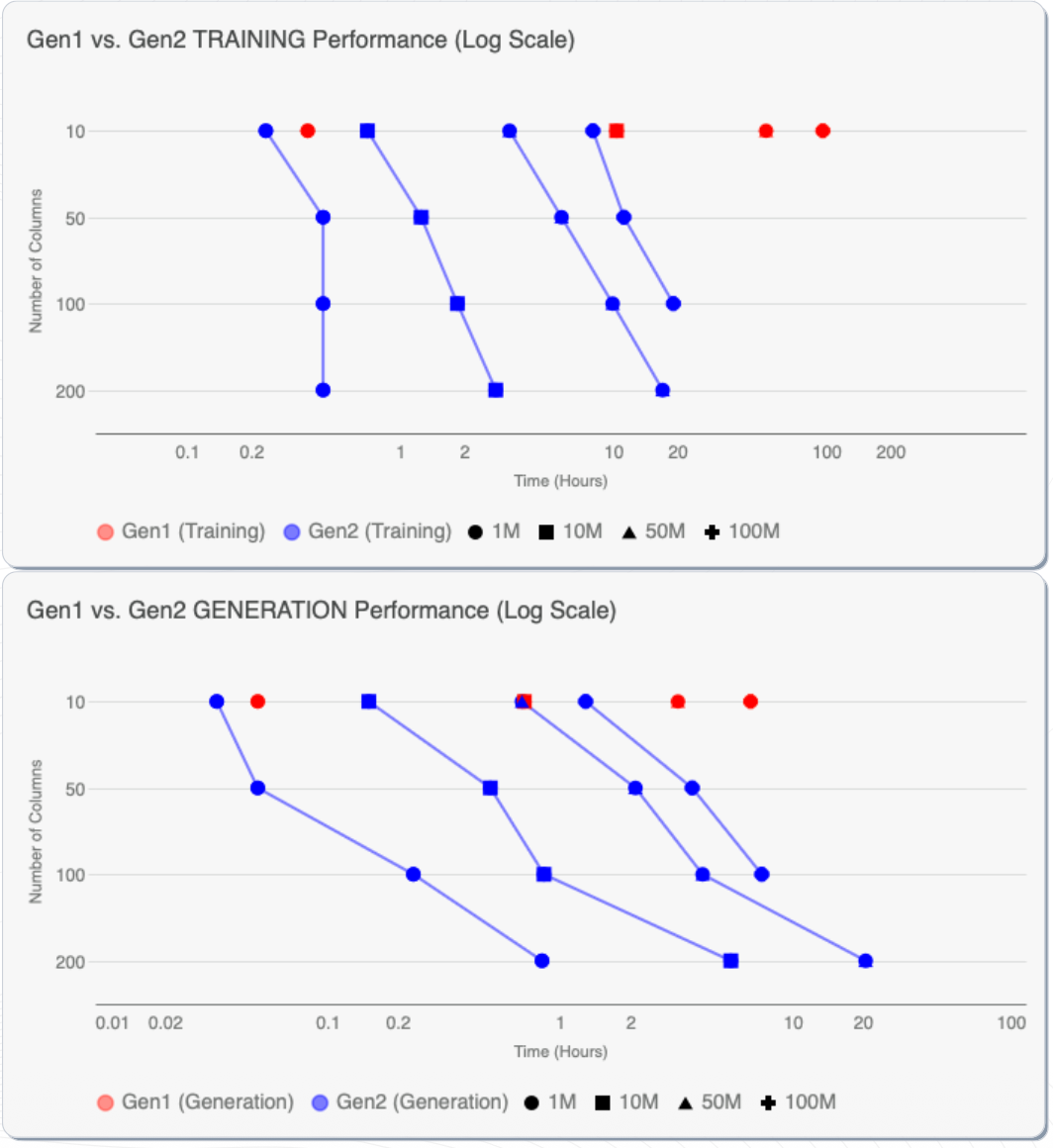
6. Performance Improvements in Synthetic Data Generation:
Next-generation synthetic data systems significantly reduce compute requirements.
Benchmark results comparing generation engines show:
- 10× faster model training
- 3× lower compute consumption
These improvements enable organizations to synthesize large enterprise datasets efficiently while maintaining statistical fidelity.
7. Synthetic Data for Enterprise AI:
By replacing raw datasets with synthetic equivalents in non-production environments, enterprises can:
- accelerate AI experimentation
- reduce compliance overhead
- prevent sensitive data exposure
- scale ML training pipelines
- enable secure data collaboration across teams
This architecture allows organizations to move AI initiatives from proof-of-concept to production faster, without compromising data privacy.
.jpeg)
